Использования регулярных выражений в гугл аналитикс
Регулярные выражения – это специальные символы, которые используются для фильтрации необходимой информации и в подстановке необходимых знаков. Следует отметить, что в google analytics регулярные выражения имеют ограничения в 256 символов. Также при работе с регулярными выражениями нужно помнить, что описывается каждый элемент строки (каждый символ) отдельно.
В google analytics вы можете использовать регулярные выражения:
1.При фильтрации данных в стандартных отчетов

2.При создании своих отчетов

3.При настройке целей

4.При создании сегментов

5.При создании групп каналов и групп контента

6.При создании фильтров

Спецсимволы
1) Точка (.)
. соответствует любому символу но только одному (букве цифре или символу)
Например: регулярному выражению гуг.л соответствуют значения гугул, гуг7л, но не гугл.

2) Умножение (*)
* соответствует 0 или 1 или более предыдущих символов (предыдущим элементом по умолчанию является предыдущий символ)
67* будет соответствовать 6, 67, 677, 6777…
Например: регулярному выражению pi*el соответствуют значения pipeline, piel, но не pixel

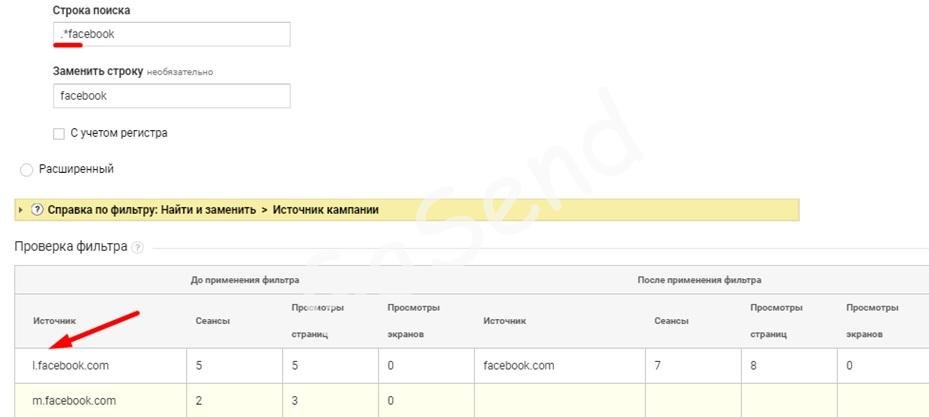
Комбинация .* соответствует 0 или множеству любых элементов.
Например, данная комбинация применяется при объединении рефералов facebook через фильтр
3) Плюс (+)
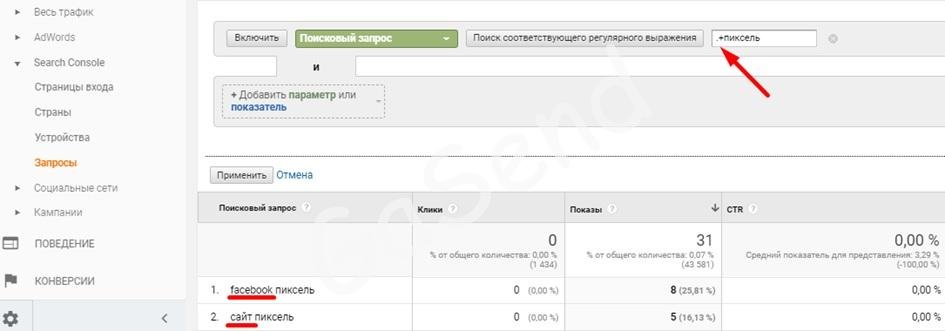
+ соответствует одному или нескольким предыдущим элементам
Например: регулярному выражению facebo+k соответствуют значения facebook, faceboook, но не facebok.

Комбинация .+ может соответствовать множеству любых символов. Разница между комбинациями регулярных выражений .* и .+ в том что при использовании .+ должно стоять хоть что то.
4) Знак вопроса (?)
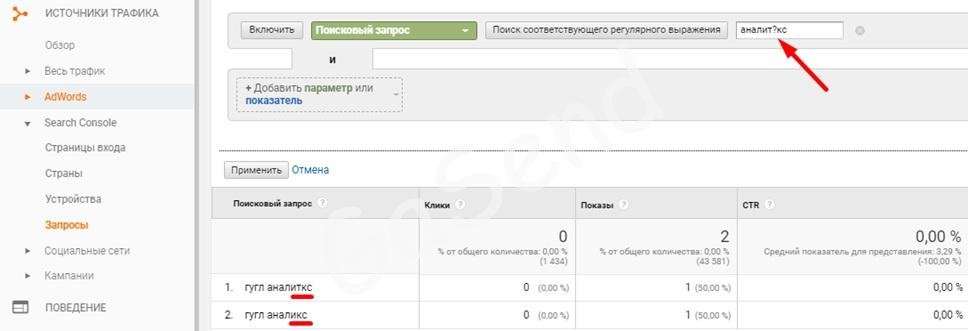
? соответствует 0 или 1 элементу.
Например аналит?кс, соответствует аналиткс , аналикс
5) Каретка
^ означает что данные, должны находиться в начале строки
Например: ^аналитикс , соответствует аналитикс, аналитикс гугл, но не «гугл аналитикс»

Если использовать [^] , тогда элементы будут исключаться.
Для примера, исключим поисковые запросы, которые начинаются с букв русского алфавита. Регулярное выражения ^[^а-я]

6) Знак доллара ($)
$ означает что данные, должны находится в конце строки
Например: bi$, соответствует owox bi, oxoxbi, но не «usability» и не owox bi attribution

7) Вертикальная линия (|)
| используется как оператор «или»
Например: При фильтр трех городов Moscow|Petersburg|Rostov

Обратите внимание, что при регулярном выражении Moscow|Petersburg|Rostov, также слова Saint Peterburg, Rostov-on-Don, St.Peterburg.
Если вам необходимо найти точное совпадения городов, тогда данное регулярное выражение будет выглядеть вот так ^Moscow$|^Petersburg$|^Rostov$

8) Круглые скобки ()
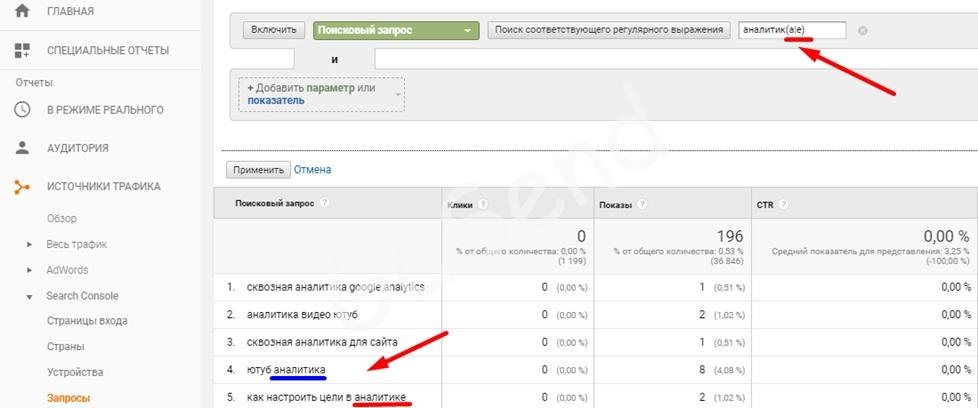
() используются, что бы создать элемент для выборки (сгруппировать элементы)
Например, аналитика(а|е) — соответствует, «аналитике» и «аналитика», не соответствует «аналитикс»
Или нужно выбрать страницы с блога с разделов аналитика и программирование о яндексе. Регулярное выражение в таком случае будет /blog/(programmirovanie|analitika)/.*yande(ks|x)

9) Квадратные скобки []
[] создания списка элементов, в котором подставляются элементы для выборки.
Например б[оау]р будет соответствовать бар, бор, бур но не баур, боар.
10) Дефис (-)
— выбор диапазона в котором подставляются числа или буквы.
Например, нужно отфильтровать айфоны с 5 по 8 версию Plus. В данном примере регулярное выражение будет Apple iPhone [5-8]s? Plus

11) Фигурные скобки {}
{} — повторение элементов несколько раз
{1,3} — последний элемент будет повторяться минимум один раз, но не больше 3 раз
{2} — последний элемент повторяется 2 раза
{0,} — соответствует регулярному выражению *
{1,} — соответствует регулярному выражению +
{1,} — соответствует регулярному выражению ?
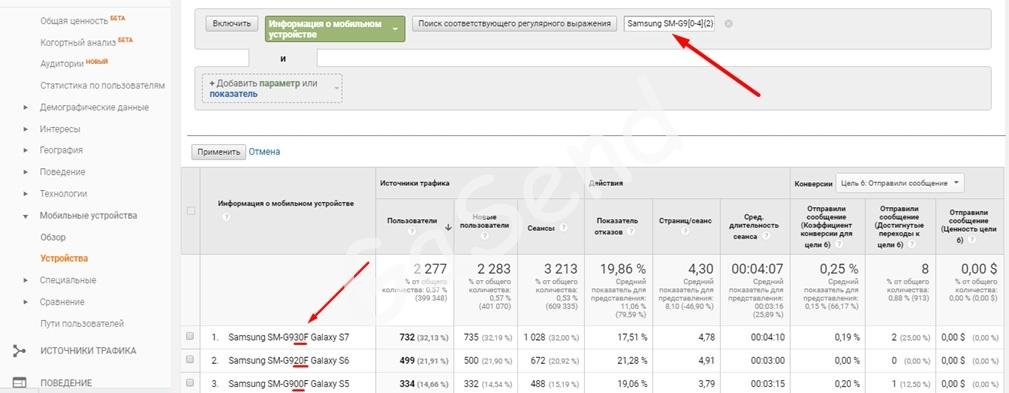
Например, фильтруем все самсунги серии SM–G серии в которых вторая и третья цифра серии не больше 4.
Регулярное выражение Samsung SM-G9[0-4]{2} , [0-4]{2} – два значения от 0 до 4
12)Обратный слэш (\)
\ преобразует элемент регулярного выражения в обычный символ
Например, если вам нужно исключить ip адреса сотрудников в офисе 13.32.56.144; 13.32.56.145; 13.32.56.146; тогда данное регулярное выражение будет выглядеть следующим образом 13\.32\.56\.14[4-6]

13) Слэш (/)
/ в регулярных выражениях – это начало или конец регулярного выражения. Например /anal.tika/. Если мы хотим, чтобы / считался как символ, а не как специальный символ регулярного выражения, тогда нужно добавить «\». По данному примеру будет \/analitika.
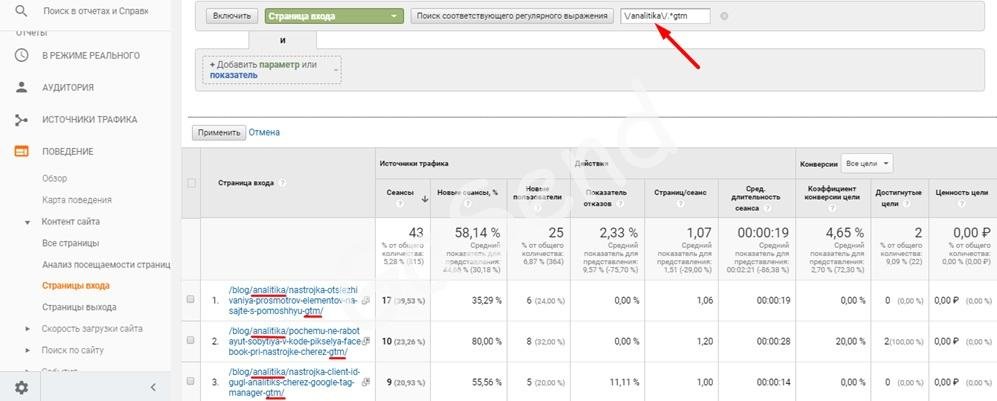
Нужно найти url страницы входа в разделе analitika в названии, которых есть слово gtm
Данное регулярное выражение \/analitika\/.*gtm
Аналогичная ситуация с символом ?, что бы он учитывался при выборке как обычный символ следует добавить «\». Пример \?
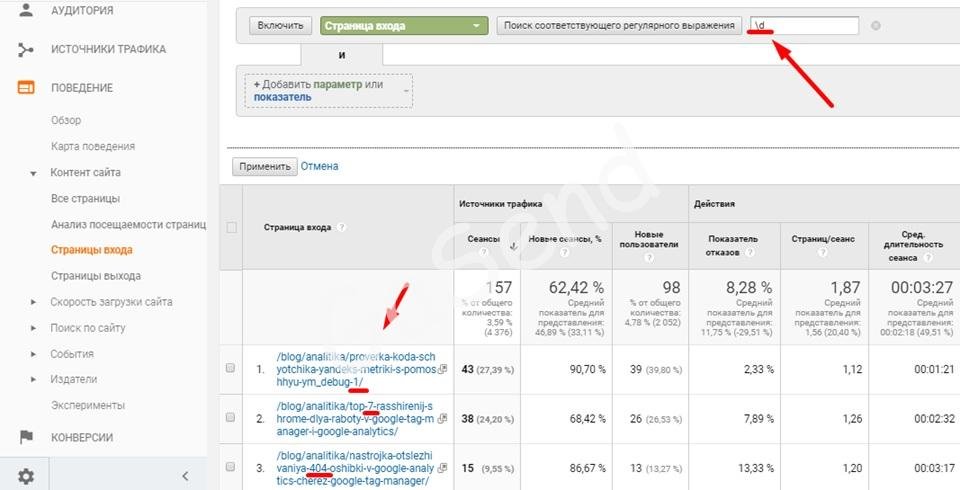
\d цифровой символ, соответствует регулярному выражению [0-9]
Например, посмотрим страницы входа в url, которых содержат цифры
\w любая буква, цифра или «_»
Например, исключаем любые буквы, цифры, и «_»

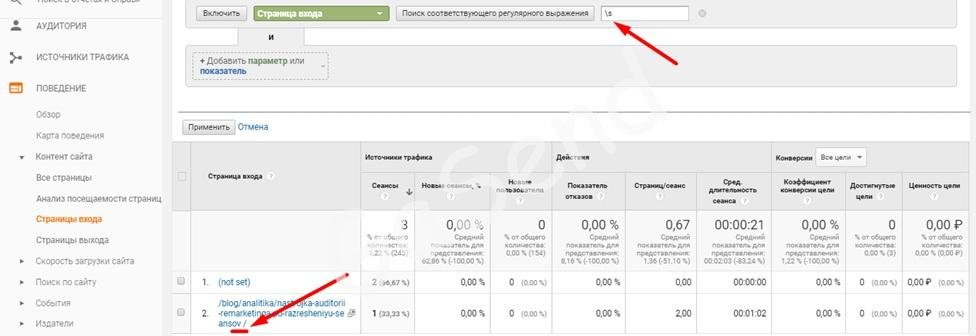
\s символ «пробела»
Разбор комбинации регулярного выражения
Например, находим поисковые запросы, которые содержат более 6 слов (более 6 пробелов). В данном примере регулярное выражения будет ^[^\s]+(\s+[^\s]+){6,} или ^[^\s]{1,}(\s{1,}[^\s]{1,}){6,}
Если его разбить, по кусочкам мы получим набор простых спецсимволов, которые описаны в данной статье:
^[^\s] – начинается не с пробела
+ — соответствует одному или нескольким предыдущим элементам
(\s+[^\s]+) – группируем элемент, который соответствует одному пробелу с одним или несколькими предыдущими элементами (+)
{6,} – повторить минимум 6 раз без ограничений

Если вы хотите задать диапазон количества слов, например 3-4 слова, регулярным выражением будет ^[^\s]+(\s+[^\s]+){2,4}$

Егор
Последние статьи Егор (посмотреть все)
- Регулярные выражения в Google analytics - 16.04.2018
- Платежные системы определяются как источник заказа - 28.12.2017
- Tag Manager Injector — позволит установить GTM на любой сайт - 27.12.2017